
Normalement, quand quelqu’un envoie des commentaires comme celui-ci, je l’ignore, mais cela arrive si souvent que cela mérite une explication, car la réponse est très simple. En fait, c’est si simple que cela devrait être évident pour des gens comme Bruce, qui a décidé hier que son malentendu méritait un avis d’une étoile sur Trustpilot :
Franchement, Trustpilot est de toute façon une source assez discutable d’avis de qualité réels, mais les mêmes commentaires sont venus suffisamment de fois par d’autres canaux pour régler ce problème une fois pour toutes. Tout commence par une question simple :
Qu’est-ce qu’une adresse e-mail ?
Vous pensez que vous le savez, et Bruce pense qu’il le sait, mais vous avez peut-être tort tous les deux. Pour expliquer la réponse à la question, nous devons commencer par la façon dont HIBP ingère les données, et c’est en fait assez simple : quelqu’un nous envoie une violation (qui ne sont généralement que des fichiers texte contenant des données) et nous exécutons l’outil open source Email Address Extractor dessus, qui transfère ensuite toutes les adresses uniques dans un fichier. Ce fichier est ensuite téléchargé sur le système, où les adresses peuvent être recherchées.
La logique de la manière dont nous extrayons les adresses se trouve dans ce référentiel Github, mais en termes simples, cela se résume à ceci :
- Il doit y avoir un symbole @
- Il peut y avoir jusqu’à 64 caractères devant (l’alias)
- Il peut y avoir jusqu’à 255 caractères après (le domaine)
- Le domaine doit contenir un point.
- Le domaine doit également avoir un TLD valide.
- Quelques autres petits critères qui sont tous documentés dans le référentiel public.
C’est tout ! Nous ne pouvons donc pas savoir s’il y a une véritable boîte aux lettres derrière l’adresse, car cela nécessiterait massif traitement par adresse, par exemple, envoyer un email à chacun et voir s’il rebondit. Pouvez-vous imaginer faire ça ? 7 milliards de fois ? C’est le nombre d’adresses uniques dans HIBP, et c’est clairement impossible. Cela signifie donc que tous les éléments suivants ont été analysés comme valides et téléchargés sur HIBP (liens profonds vers les résultats de la recherche) :
- test@exemple.com
- _test@google.com
- putain de perte de temps@foo.com
J’aime particulièrement ce dernier, car il semble être un sentiment que Bruce exprimerait. C’est aussi un excellent exemple, car ce n’est clairement pas « réel » ; l’alias est un peu révélateur, tout comme le domaine (“foo” est couramment utilisé comme espace réservé, de la même manière que nous pourrions également utiliser “bar”, ou les combiner comme “foo bar”). Mais si vous suivez le lien et voyez la faille dans laquelle il a été exposé, vous verrez un nom très familier :
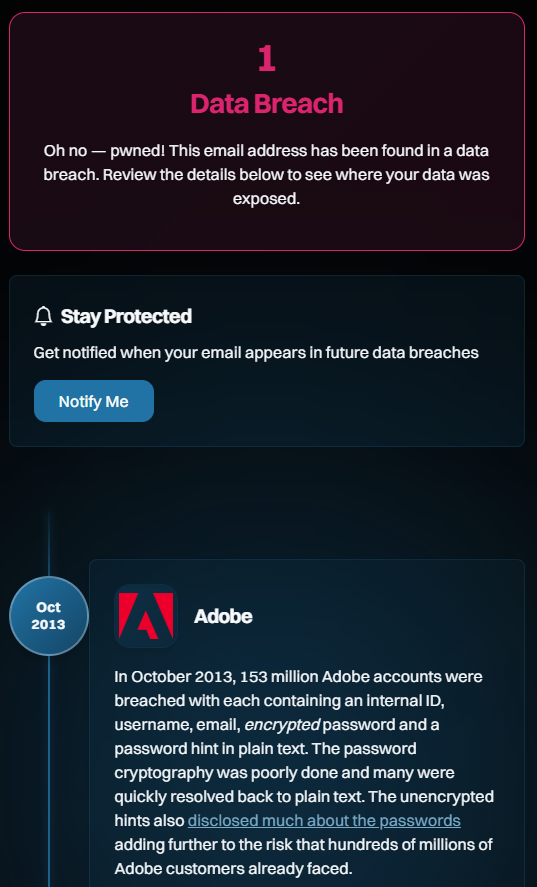
Ce qui nous amène à la question suivante :
Comment les « fausses » adresses e-mail se retrouvent-elles sur de vrais sites Web ?
Des questions, Bruce ? Cela s’explique aussi facilement que pourquoi nous l’a considéré comme une adresse valide et l’a ingérée dans HIBP : l’adresse e-mail a une structure valide. C’est tout. C’est comme ça que l’information est arrivée à Adobe et c’est ainsi qu’elle a ensuite été intégrée à HIBP.
Ah, mais Adobe ne devrait-il pas le faire ? vérifier l’adresse ? Je veux dire, ne devraient-ils pas envoyer un e-mail à l’adresse du type : “Hé, êtes-vous sûr de vouloir vous inscrire à ce service ?” Oui, ils devraient le faire, mais voici l’astuce : Cela n’empêche pas que l’adresse email soit ajoutée à votre base de données en premier lieu ! La façon dont cela fonctionne normalement (et c’est ce que nous faisons avec HIBP lorsque vous vous inscrivez au service de notification gratuit) est que vous entrez l’adresse e-mail, le système génère un jeton aléatoire, puis les deux sont enregistrés ensemble dans la base de données. Un lien avec le jeton est ensuite envoyé par courrier électronique à l’adresse et utilisé pour vérifier si l’utilisateur suit ce lien. Et s’ils ne suivent pas ce lien ? Nous supprimons l’adresse e-mail si elle n’a pas été vérifiée au bout de quelques jours, mais Adobe ne le fait évidemment pas. La plupart des services ne le font pas, alors nous y sommes.
Comment puis-je vraiment être sûr que les vraies fausses adresses ne sont pas dans HIBP ?
C’est aussi Cela va paraître profondément évident, mais vraiment adresses e-mail aléatoires (pas “thisisfuckinguseless@”) n’apparaîtra pas dans HIBP. Voulez-vous tester la théorie? Essayez le générateur 1Password (oui, Bruce, ils sponsorisent aussi HIBP) :
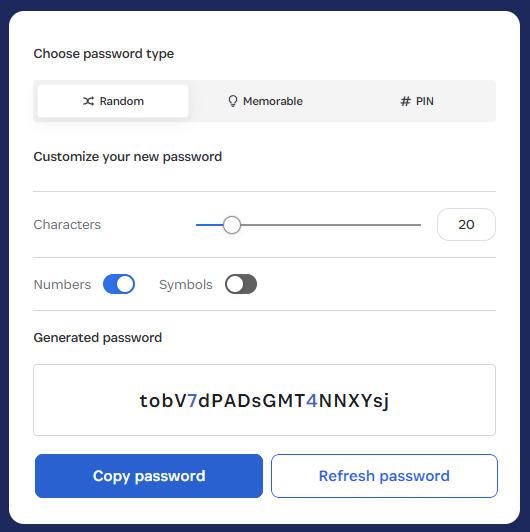
Maintenant, cliquez-le sur le domaine foo.com et effectuez une recherche :
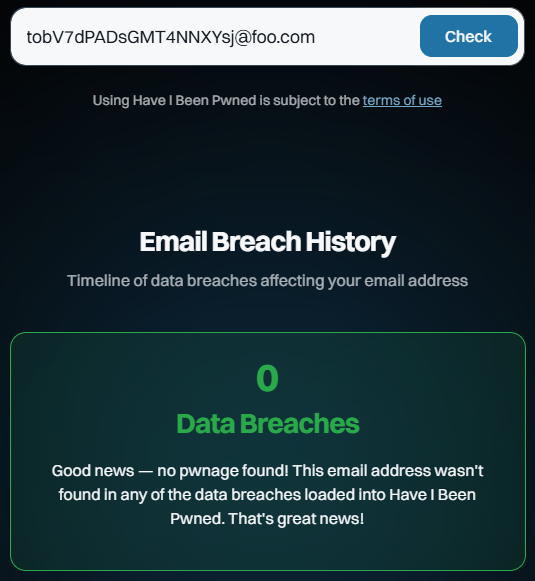
Hé, tu peux regarder ça ? Et vous pouvez continuer à le faire encore et encore. Vous obtiendrez le même résultat car il s’agit d’adresses fabriquées que personne d’autre n’a créées ou saisies sur un site Web qui a ensuite été piraté, prouvant ipso facto qu’elles ne peuvent pas apparaître dans l’ensemble de données.
Conclusion
Aujourd’hui, c’est le 12e anniversaire de HIBP et j’ai particulièrement contesté l’avis de Bruce car il remet en question l’intégrité avec laquelle je gère ce service. C’est maintenant le 218ème article de blog que j’écris sur HIBP, et au cours des douze dernières années, j’ai tout détaillé, de l’architecture aux considérations éthiques en passant par la façon dont je vérifie les violations. Il est difficile d’imaginer être plus transparent sur la façon dont ce service est géré, et sur la base de ce qui précède, il est très facile de réfuter les Bruces du monde. Si vous avez lu jusqu’ici et que vous aimeriez laisser un avis précis et factuel, ce serait fantastique 😊

